

Applying artificial intelligence in the real-world settings extends far beyond the controlled environment of academic research, Kaggle competitions, or personal experiments with prototype models in popular Python AI/ML frameworks. When AI steps out of the lab and into our daily lives, the stakes rise significantly due to the real-world consequences its applications can entail.
While AI technology has become readily accessible and most organizations possess some form of data, crafting a quick solution can often seem deceptively simple. Yet, advancing these solutions by integrating an AI model or system into a live operational environment typically involves a labyrinth of complexities.
The team at Oxide AI has compiled some common challenges encountered in real-world AI deployments, along with insights on how to navigate these hurdles. It is important to note that this overview is not exhaustive; every industry presents its unique set of challenges.
In this blog post, we focus entirely on the real-world applications of AI models, saving the technical operations for another post. While there are many other perspectives to consider, such as responsible, ethical, and environmental aspects, our insights provide a solid foundation for understanding the essential considerations in nearly every AI implementation.
1) Model Overfitting
A machine learning model that excels at interpolation might be overfitting, performing very well on training data but poorly on unseen data. This suggests that the model has learned the specific details and noise of the training data, rather than capturing the underlying general patterns necessary for effective extrapolation.
What to do:
2) Unpredictability in Extrapolation
Interpolation enables neural networks to predict within the range of the training data, and generative AI (like LLMs) models can indeed be quite powerful in predicting outcomes based on learned data distributions.
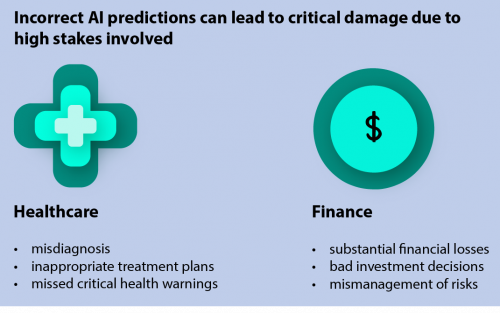
However, when neural networks extrapolate, they attempt to predict based on patterns beyond previous observations. This can lead to unpredictable or completely incorrect outputs, as the network essentially “guesses” relationships in regions outside its training data. In critical sectors, such as healthcare or autonomous driving, erroneous extrapolations can result in severe consequences.
The challenges of relying on deep learning in finance automation also stem from this issue. With inputs constantly evolving beyond training data, future predictions based solely on historical data for training become less viable.
What to do:
3) Inherent Biases
Both interpolation and extrapolation are susceptible to biases inherent in the training data. When training data is biased, predictions—whether within the data range (interpolation) or extending beyond it (extrapolation)—are likely to reflect and potentially amplify those biases.
What to do:
4) Underestimating the Complexity of Real-World Problems
Many real-world AI problems involve high levels of complexity that go beyond what can be handled through simple interpolation or extrapolation. These scenarios demand an understanding of intricate causal relationships, contextual nuances, and multi-dimensional data, aspects that often lie beyond the capabilities of current AI models.
What to do:
5) Error Propagation
Real-world AI systems often use multiple AI models in sequence. For instance, one AI model might extract facts from documents, while another utilizes this data for estimations. This approach can create a chain of errors, with inaccuracies accumulating at each stage. Similarly, error accumulation can also occur in poorly designed LLM-based solutions that repeatedly use output from past trials as input for new ones. When errors occur early in the model chain or in the training data, they have potential to propagate and magnify, leading to significant inaccuracies or even system malfunctions. This can compromise system robustness, as final output validation may fail to capture these cumulative errors effectively.
What to do:

